

La scomparsa del lavoro, l’automazione totale e altre favole
Ti spiego il dato - 🦩 Summer edition 2023 #3 - ultima!

Stai leggendo la versione estiva della newsletter
È la terza e ultima puntata con guest writer: abbiamo oggi Riccardo Angius, che fa ricerca da tempo sulla tecnologia e i suoi limiti, e chiarisce ancora una volta il problema di attribuire caratteristiche umane alle macchine. Conosco Riccardo online da tempo, ma a sorpresa l’ho ritrovatə a Padova in uno dei festival universitari più belli a cui mi sia capitato di partecipare, il Je t’aime: musica elettronica, transfemminismo e inclusione. Oltre al piacere di parlare di femminismo dei dati in quel contesto, mi sono “portata a casa” anche questo numero estivo :)
E arrivata alla conclusione della summer edition sono felice che anche quest’anno, come nel 2022, la mia pausa si sia arricchita di punti di vista diversi, permettendomi di regalare alle persone iscritte (tantissime nuove in questi mesi, grazie!) delle letture di qualità.
Io torno a scrivervi mercoledì 6 settembre, con una bozza praticamente pronta. Solo che vi lascio ancora il tempo di recuperare le newsletter arretrate.
Buona lettura!
La scomparsa del lavoro, l’automazione totale e altre favole
Ciao! Mi chiamo Riccardo, faccio ricerca e sviluppo per l’analisi indipendente degli algoritmi opachi usati dai vertici del potere socio-economico. Ho tre borse di ricerca alle spalle tra reti neurali, sociopsicolinguistica computazionale, sovraffidamento ai sistemi digitali in ambito medico, auditing sociotecnico, benchmark statistici e causali dei sistemi di apprendimento automatico.
Dopo dieci anni ormai in questo arcobaleno interdisciplinare che chiamiamo “intelligenza artificiale”, la mia indole scientifica è inquieta: ho attraversato questa evoluzione collettiva sia in un ruolo tecnico-matematico, sia in una vita per molti aspetti ai margini della società, e sento particolarmente la responsabilità di includere nel dibattito pubblico quanto imparato da questa prospettiva.

"A Woman's Work Is Never Done" (1974, Red Women’s Workshop)Sentiamo parlare sempre più spesso della scomparsa del lavoro, dovuta all’automazione totale che verrà. È già qui, oppure sta per arrivare? Aspetta un secondo. Butto la pasta? La matematica, in realtà, nonostante l’estrema insistenza del marketing, non sembra offrire grandi certezze riguardo l’arrivo della singolarità, l’auspicata intelligenza superiore e autonoma dal genere umano.
È in questo contesto che nell’autunno scorso OpenAI ha rilasciato l’applicazione ChatGPT: un software capace di produrre, in risposta a una domanda, un testo spesso indistinguibile dagli scritti di una persona. È questa la strada verso l’automazione totale, dove i software e le macchine faranno tutto al posto nostro? La risposta sembra essere negativa, vista la quantità di falsità che producono e che chi vende abbonamenti a questi servizi si ostina a liquidare come “allucinazioni”: un termine pasticciato e relativo all’esperienza umana che confonde ancora di più la questione, invece che chiarirla.
L’antropomorfizzazione delle macchine e, viceversa, la meccanizzazione delle persone, hanno una lunga tradizione di cui è ormai forse impossibile rintracciare l’origine, ma che continua a scontrarsi con la realtà materiale che ci circonda. Noi non siamo macchine, come ho spiegato altrove, ma perché sappiamo con certezza che le macchine - sia quelle tangibili che quelle astratte - non potranno mai essere seriamente considerate né umane né intelligenti?
Il teorema di Rice
Nel 1951 il signor Henry Gordon Rice consegna all’università di Syracuse, New York, la sua tesi di dottorato, contenente la prima dimostrazione dell’omonimo teorema, alla quale nei decenni se ne sono susseguite altre, analoghe, per tutti i sistemi di calcolo automatico. Il cuore delle dimostrazioni è l’impossibilità di sapere a priori, per ogni possibile insieme di dati, se un algoritmo può raggiungere il risultato richiesto e “spegnersi” da solo - ad esempio dopo aver terminato la generazione di una rete neurale - oppure se sarà necessario che una persona in carne e ossa ne limiti il tempo massimo di esecuzione, per ottenere almeno un risultato approssimato. Senza poter sapere questo, dice Rice, possiamo allora scordarci di attribuire qualsiasi altra proprietà complessa all’algoritmo, come ad esempio la garanzia che generi solo reti neurali capaci di rispondere sempre correttamente, senza contenuti misogini o razzisti, diagnosi mediche errate, o più in generale informazioni sbagliate su unità statistiche ignote al momento della progettazione. Per accertare questa e altre proprietà particolari, una o più persone dovrebbero analizzare quanto prodotto caso per caso ovvero, per l’algoritmo nell’esempio, analizzare ogni rete neurale generata, per ogni suo possibile input. Un fatto noto da tempo, ma mistificato, anche in Silicon Valley.
Anche intuitivamente, per definire esaustivamente qualsiasi concetto, nemmeno l’insieme completo delle definizioni prodotte nei dizionari di tutto il globo terraqueo è sufficiente. È chiaro il legame indissolubile con l’infinito tessuto culturale - fatto di relazioni, corpi, ricerca, libri e dibattiti - che continuamente, in diversi contesti, elabora e confligge i significati per co-significarne anche di nuovi, con definizioni infinite che si richiamano a vicenda, incontenibili in stringhe di bit o di testo di dimensione limitata. Per poter interpretare ogni risposta dell’algoritmo, alla fine, siamo noi a doverci ricordare quali assunti e quali definizioni limitate abbiamo scelto per inquadrare il problema. Limiti dovuti anche alla competenza individuale e collettiva di chi progetta, confinante e sfumata con le altre competenze possedute in misura ancora più parziale, perché parziali sono le relazioni dirette che abbiamo con la totalità dell’universo su cui la nostra realtà si regge. Con ancora meno rigore per i diffusi significati che non potremmo mai più ricostruire completamente, ma da cui derivano le prassi oggi annunciate spesso con un sonoro “abbiamo sempre fatto così’.
Senza il sudore delle mani sulla tastiera e tutte le altre interazioni umane e ambientali - come ad esempio richiedono le attività di produrre i dati e scrivere il codice per co-significare l’obiettivo del software - gli impulsi elettrici all’interno della macchina producono così effetti, ma non hanno significato a sé.
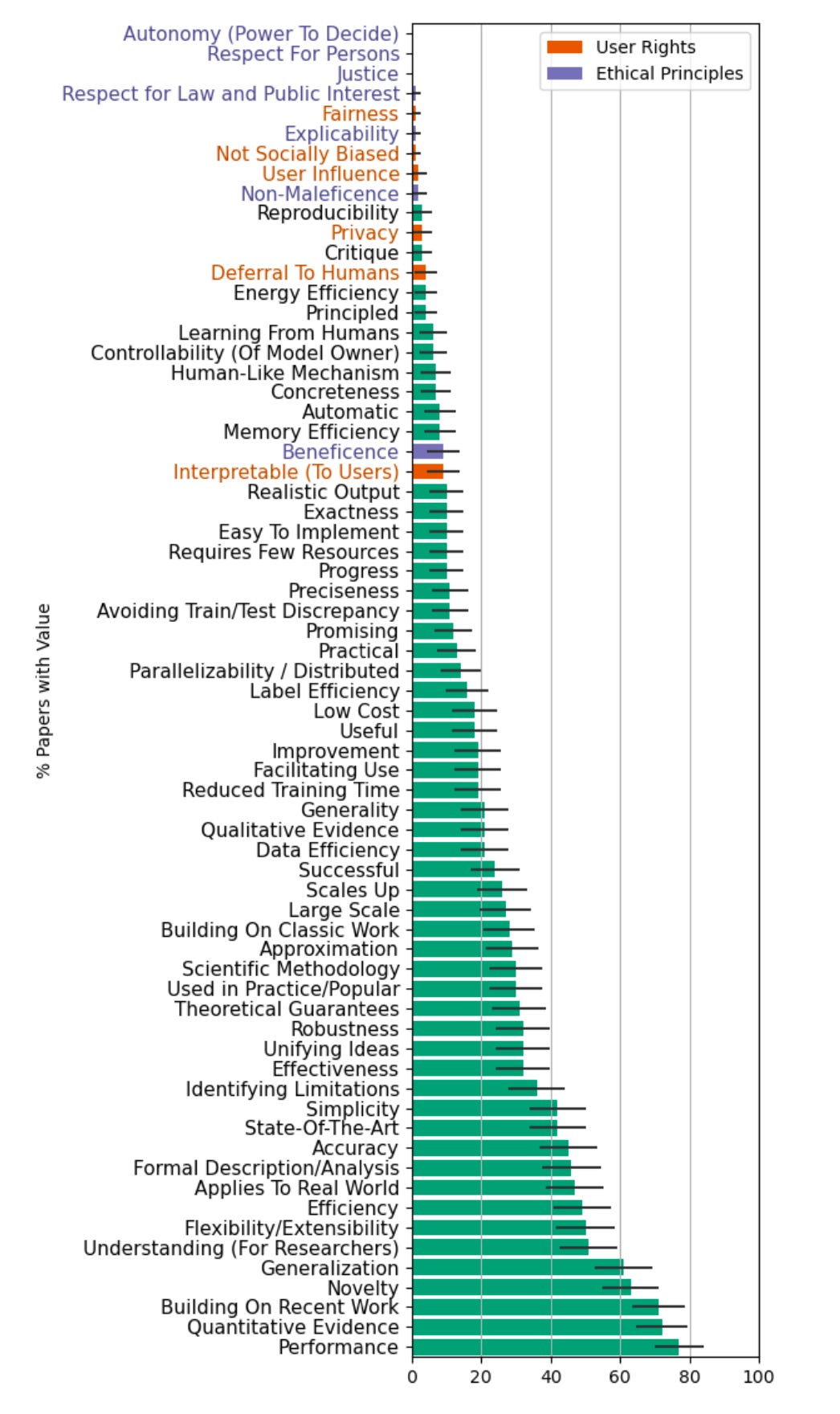
Come operiamo la co-significazione? Vediamo qui, ad esempio. i valori rilevati da Abeba Birhane negli articoli più citati delle maggiori conferenze sull’apprendimento automatico, NeurIPS e ICML, che definiscono una parte del senso collettivo della ricerca scientifica.Ma allora perché parliamo di intelligenza artificiale, se nemmeno codifica i significati? La statistica e altre discipline matematiche hanno spesso permesso negli anni di ricondurre parzialmente l’elaborazione semantica a quella sintattica, consentendo in molti casi automazioni davvero straordinarie. Ma sono in realtà solo gli ennesimi esempi di un trucchetto che in matematica chiamiamo “problemi giocattolo”: non avendo strumenti matematici sufficienti per risolvere un problema in modo esatto, si ripiega su una soluzione subottimale. Non la migliore, ma la migliore approssimabile secondo gli standard richiesti e gli strumenti a disposizione: rimane fuori, ancora una volta, capire chi decide gli standard e secondo quali priorità.
I significati dunque non sono solo strappati lungo i bordi della competenza di chi li impiega per inquadrare un problema specifico ma, come spiega Silvia Crafa, devono anche passare attraverso il filtro delle approssimazioni operate dal particolare algoritmo scelto per affrontare il problema: praticamente la fotocopia della fotocopia, rispetto al significato originale.
La produzione di falsità non è allora una “allucinazione”, ma un effetto collaterale strutturale all’elaborazione sintattica dei testi, irricevibile come fondamenta della singolarità che la bolla finanziaria corrente sostiene possa arrivare persino a governarci.
Ed è chiaro quanto pericoloso e irresponsabile sia adottare questi software per produrre testi e contenuti per i quali non si ha competenza o strumenti sufficienti per accertarne la bontà.
A salvarsi non sarà chi ha mera competenza di quali prompt fornire a ChatGPT, ma chi continuerà a vivere, custodire ed elaborare la cultura che oltre a dare un significato a noi stessə, ci permette di validare in modo partecipativamente robusto la tecnica e le simulazioni digitalizzate, ovvero chi conosce e abita i contesti oggetti di simulazione senza subalternità al digitale. Se non rivendichiamo questo, saremo condannatə a essere governatə dall’incompetenza e dalle asimmetrie di potere nascoste dietro le automazioni. La produzione di falsità è però anche più probabile per gli argomenti meno digitalizzati. Come accade alle identità e istanze di minoranze e organizzazioni sociali che faticosamente lavorano senza risorse per spazio adeguato sulla stampa, ovvero la fonte primaria, dopo le enciclopedie, per orientare i software nella stima della parola successiva più probabile.
A chi conviene dunque parlare di allucinazioni? Sul lungo termine, a nessuno: sappiamo purtroppo bene come ignorare l’incertezza dovuta alle approssimazioni possa portarci a effetti devastanti a livello globale. Sul breve, se niente sarà fatto, i costi delle falsità strutturali saranno scaricati ancora su chi è fuori dal privilegio del potere socio-economico. Saranno, loro, noi, a dover operare gratuitamente lavoro di cura per correggere le prevedibili conseguenze, su larga scala, di un lavoro produttivo ingenuo e illuso che le transazioni economiche (quali sono per la gran parte quelle digitali oggi) non comportino sempre anche significative interazioni sociali.
Non è infatti difficile immaginare come, dentro un piano editoriale per dei post su Instagram, o un riassunto di una pubblicazione scientifica, generati automaticamente per altri temi, possano trovare spazio cliché poco problematizzati dai mass media, come ad esempio sono oggi la concezione della donna come madre prima di tutto, il tropo della vocazione turistica come unica salvezza per i territori devastati dal colonialismo, la risibile responsabilità individuale nel collasso ecologico globale, oppure ancora tante altre belle cose che continuano a chiuderci impercettibilmente dentro lo spazio delle possibilità di un mondo terribile.

La prima parte di una risposta di ChatGPT, che innocuamente suggerisce ulteriore sovra turistificazione, senza alcun cenno all’ingiustizia di un’economia che svaluta il lavoro cognitivo locale, de-finanziata su istruzione e ricerca universitaria, e fatta già di estrazionismo, lavoro povero e basso valore aggiunto.L’automazione totale non è dunque né realistica né auspicabile, e il lavoro di cura delle risposte prodotte dalle macchine dovrà essere sempre preventivato, distribuito e retribuito adeguatamente. A meno di non voler ulteriormente sfruttare e rendere invisibile la catena globale della cura, già costretta a mettere le toppe per limitare i danni del modello economico esistente.
È più facile immaginare la fine del mondo, che la fine della tecnica e del mercato deresponsabilizzati dall’essere umani? Forse, allora, ci conviene tenere stretto il diritto all’immaginazione delle complessità che sfuggono all’io, al noi e all’oggi. I diritti, però, non si chiedono, si prendono.
Ti è piaciuta questa edizione della Summer edition? Recupera anche i due numeri precedenti in cui hanno scritto Josephine Condemi e Paola Chiara Masuzzo.
Ci risentiamo a settembre!
Rispetto all'uso attuale della tecnologia si potrebbe partire dalla domanda di Huyskes: “Un essere umano farebbe una scelta simile?” per vivere in un mondo più giusto. Ma come sottolineato da Angius nel XXI secolo (almeno in questi primi anni) siamo più propensi a diventare macchine che a utilizzare le macchine per diventare esseri umani migliori