

Cosa vuol dire lavorare sugli Epstein files come "dati di pubblico interesse"
I dati senza contesto e senza comunità non ti portano da nessuna parte

In questo numero: come si trova il senso dentro due milioni di documenti quando le testimonianze delle vittime di abusi di Jeffrey Epstein sono arrivate già trent’anni fa. (Non ci sono trigger warning nel testo che segue, a parte questo).

Per SkyTG24 ho commentato i dati sulle persone senza dimora. Ricordate la notte della conta, con i seimila volontari in 14 città italiane? Ci sono i primi risultati quantitativi. Sono circa 10mila le persone contate, lo 0,11% della popolazione residente (in media), ma con differenze territoriali: Genova e Venezia si avvicinano o superano lo 0,14%, mentre Reggio Calabria scende allo 0,019%. Nelle strutture il 78,6% sono uomini, le donne il 21,4%. Ma, come è stato fatto notare alla presentazione del report, il dato va letto tenendo conto che i centri per donne vittime di violenza o tratta sono stati esclusi dalla rilevazione: il numero reale di donne in condizione di fragilità e povertà è più alto. Continua su Sky Insider.
Dove mi trovi prossimamente
16 aprile, Milano: 40 anni di Cadmi, alle 10, sala Alessi, in piazza della Scala.
18 aprile, Roma: all’Auditorium Parco della Musica, c’è il Festival delle Scienze di Roma, e mi trovi all’evento “Dati bugiardi”.
8 maggio, Pesaro: al festival Percorsi, un “drink talk” per una cittadinanza digitale più critica e femminista.
LAVORIAMO INSIEME? Puoi portarmi in azienda per un evento, contattarmi per una consulenza su come raccontare meglio i tuoi dati o promuovere il tuo lavoro su questa newsletter con un’inserzione. Scrivi a progetti@donatacolumbro.it per i dettagli.
Sei tra le 14848 persone che leggono la newsletter. Nell’ultima puntata abbiamo parlato di atti di resistenza che consistono nel “rifiutare i dati”:

So che è difficile da digerire. La violenza. L’abbandono. Le decisioni sbagliate. L’autolesionismo. Immagina se un filmato di traumi come questo ti scorresse in testa continuamente, come succede a me, e non solo sulle pagine di un libro che puoi mettere da parte se ne hai bisogno, anche solo per un momento, per calmare i nervi.
Virginia Roberts Giuffre, Nobody’s girl (2025)
Epstein files: big messy data, testimonianze, inchieste di comunità
La prima volta che ho ascoltato le parole di Virginia Roberts Giuffre era nel 2020. Roberts (userò solo questo cognome, non quello del marito, che ha accusato di violenze negli ultimi mesi della sua vita) parlava nella docuserie Jeffrey Epstein: Filthy Rich, ancora disponibile su Netflix. Come ha poi raccontato anche nel suo memoir, Nobody’s girl (Bompiani 2025) pubblicato dopo la sua morte, a 16 anni era stata avvicinata da Ghislaine Maxwell mentre lavorava a Mar-a-Lago, la residenza di proprietà di Donald Trump, e poi portata nella villa del miliardario Jeffrey Epstein con la promessa di imparare tecniche per diventare massaggiatrice professionista. La sua vita non era mai stata facile, i rapporti con gli uomini erano stati segnati per sempre prima dagli abusi familiari, poi da quelli nelle strutture in cui veniva puntualmente rinchiusa con progetti di “recupero” che non erano mai tali.
Non sono qui per riportare tutti i fatti della sua vita, ma già quella docuserie - che ho cominciato a vedere probabilmente sull'onda dell'enorme mole di testimonianze emerse con le mobilitazioni del MeToo - metteva in fila tutta una serie di prove ed evidenze che chiunque lavori nel contrasto alla violenza conosce bene: la prima cosa difficile è rendersi conto di essere vittima di una violenza. Di subire qualcosa che non è normale. Per molte di quelle bambine e ragazze entrate nella casa degli orrori (la residenza di El Brillo Way, Palm Beach), e poi portate nella cosiddetta isola dello stupro (Little St. James), e nelle varie altre dimore del trafficante miliardario in giro per gli Stati Uniti e l’Europa, non era possibile uscire, tornare indietro, denunciare, evitare di essere soggiogate nella rete di abusi e nello schema ponzi che poi avrebbe portato alcune di loro a reclutare altre vittime.

Il memoir di Virginia Roberts da questo punto di vista è un “manuale” perfetto per chiunque abbia a che fare con il sistema penale: lei ammette tutte le sue difficoltà, i suoi sbagli, senza universalizzare, ma rende davvero difficile automatizzare il pensiero per cui ci si chiede “allora perché non sei andata via?”
Quando sono usciti gli Epstein files mi sono fatta la stessa domanda di Giulia Paganelli Evastaizitta, nella prima puntata della sua incredibile serie di newsletter La Fabbrica dei corpi, che vi consiglio di recuperare:
Perché valgono più le email di un morto che trent'anni di testimonianze delle vittime?
La risposta risiede sia nel valore che diamo alla parola delle donne che denunciano, sia in quello che attribuiamo ai dati, soprattutto quando si presentano nel formato con cui sono stati rilasciati gli Epstein files: big (messy) data.
Per la filosofa della scienza Sabina Leonelli, coautrice di Data &Society e de “La ricerca scientifica nell’era dei Big Data” (Meltemi 2019), i big data non sono solo dati in grandi quantità, ma dati che si presentano con una serie di caratteristiche che sono riassunte nello schema delle 5 V: il volume, la varietà di forme diverse, la velocità con cui vengono prodotti, l’accuratezza o veridicità con cui ci promettono di rappresentare la realtà, il valore che le diverse comunità possono attribuire loro, e la volatilità, la capacità dei dati di rimanere leggibili nel tempo nonostante l'evoluzione tecnologica. Per Leonelli c’è un aspetto relazionale, in più, che dobbiamo considerare, quando definiamo i big data:
dati di tipi e provenienze diversi che vengono messi in relazione l'uno con gli altri, spesso in forma digitale e in modi che si prestano all'apprendimento automatico, così da produrre nuove forme di analisi e conoscenza.
Ma la retorica tipicamente collegata ai big data è illusoria,
di accumulazione del sapere in maniera induttiva.
Una retorica per cui i big data vengono associati a un'accelerazione nella produzione di conoscenza e nella sua traduzione in soluzioni pratiche, quasi che la quantità di dati possa garantire da sola la comprensione e l'intervento.
Nel caso degli Epstein files l'illusione funziona in modo speculare: la mole di documenti rilasciati dal DOJ crea l'impressione che la verità sia finalmente accessibile, che basti cercare.
Ci ricorda ancora Paganelli:
Il senso degli “Epstein files” va collocato dentro questa cornice. La pubblicazione di documenti non coincide con la scoperta improvvisa di una verità rimasta nascosta, coincide con il modo in cui porzioni di materiale diventano pubbliche in ritardo, a blocchi, attraverso procedure di desecretazione, redazioni e rilasci massivi.
Una interpretazione e una soluzione tecnologica di comunità
Come già scrivevamo io e Paola Chiara Masuzzo sul dataset dei femminicidi prodotto dalla Rai, il lavoro di comunità permette di dare senso ai data point presenti in un dataset o nell’insieme di documenti di varia natura quali sono gli Epstein files.
Il problema è come questo lavoro viene portato avanti. Quando arrivano sulla scena dati in grande quantità, a flusso continuo (ricordiamo la pandemia, sì?), chi sa manipolarli con competenze tecniche non resisterà alla tentazione di farlo. C’è chi ha trasformato le email in un’interfaccia di gmail pronta all’uso, chi ha pubblicato tutto su Github, ecc ecc.
La disponibilità di dati in grandi quantità incentiva la creazione di sistemi computazionali sempre più potenti per poterli analizzare, e a sua volta la creazione di questi sistemi incentiva investimenti nell’accumulo dei dati.
scrive ancora Leonelli.

Qui parliamo di file di centinaia di pagine, testo sfocato o ruotato in orizzontale, bonifici senza contesto, email con i nomi oscurati, registri di volo con solo le iniziali. La quantità non produce conoscenza, produce disorientamento.
E quindi, cosa ce ne facciamo? Come uniamo disponibilità di dati con la strumentazione tecnica che ci permette di comprenderli alla capacità di analizzarli con contesto e soprattutto senza dimenticare la voce delle vittime, che per prime avevano davvero esposto il sistema di abusi nella sua interezza?
A questa domanda ha risposto, nel suo modo, l'utente di Reddit che si fa chiamare "Eric Keller", pubblicando il sito epsteinexposed.com.
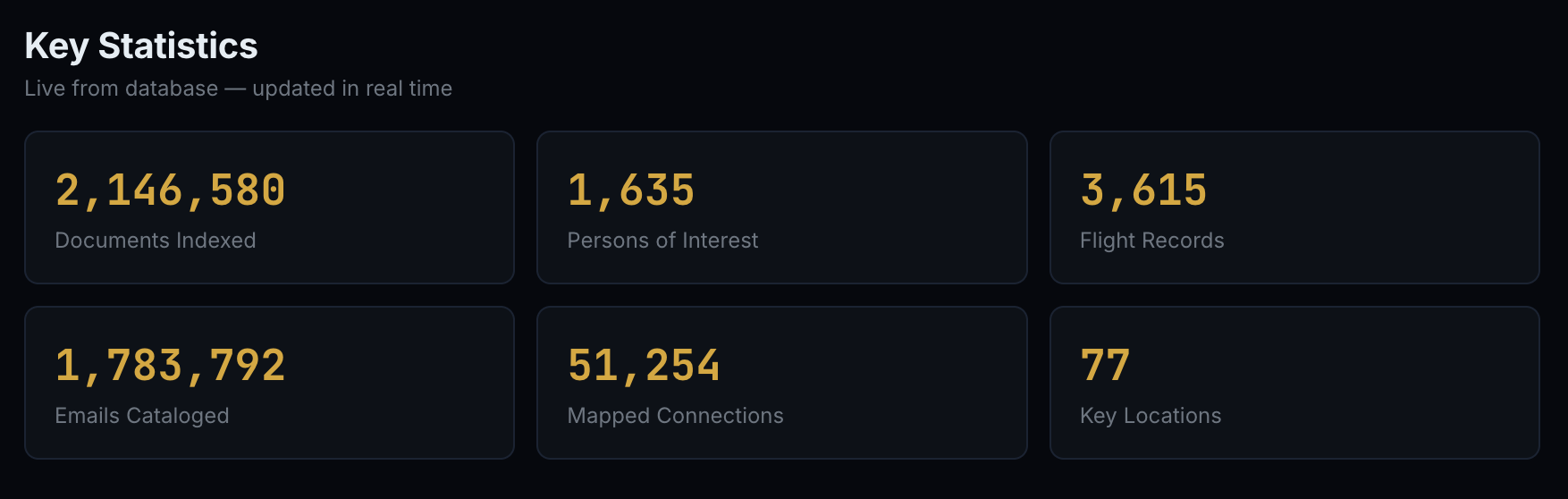
Keller (uno pseudonimo) ha indicizzato 2,15 milioni di documenti, catalogato 1.500 nomi presenti nei file e mappato decine di migliaia di connessioni. È anche una persona sopravvissuta ad abusi nell’infanzia, ha raccontato a Wired. È per questo che “non riesce a distogliere lo sguardo dall’orrore contenuto in quei fascicoli”.
E allora costruisce. La conoscenza incarnata dell'abuso lo rende un data curator diverso dagli altri, forse, non solo più motivato, ma capace di cogliere dettagli che chi non ha quella chiave di lettura potrebbe sottovalutare o non riconoscere.
“Invece di pensare a una categoria di documenti alla volta, ho cominciato a pensare alla rete. Come colleghi una persona che appare in un'email a un volo su cui era presente, a un bonifico, a una deposizione che ha rilasciato? Quel problema di riferimenti incrociati era quello che volevo risolvere”, dice Keller a Wired. E ancora: “La risposta ti dice qualcosa di preciso. Esiste una comunità reale di persone che da molto tempo cerca di arrivare alla verità, e il sito ha dato loro qualcosa che prima non avevano”.
Epsteinexposed.com, cosa c’è dentro
Keller pensa costantemente alle sopravvissute, immagina cosa possa significare per loro trovare documentazione che confermi: sì, è successo davvero, sì, il mondo lo sa.
Le fonti usate da Keller e dalle persone che oggi collaborano al sito sono esclusivamente atti ufficiali: rilasci del dipartimento di giustizia ai sensi dell'Epstein Files Transparency Act, fascicoli giudiziari federali e statali, documenti FBI ottenuti tramite FOIA, registri di volo con numeri di coda FAA verificati, documenti del Comitato di Supervisione della camera, e registri finanziari tra cui estratti conto di Deutsche Bank e JPMorgan.
Ogni documento viene sottoposto a un processo di 9 step: acquisizione, verifica crittografica, estrazione OCR del testo, sintesi strutturata, riconoscimento delle entità, collegamento incrociato, indicizzazione semantica, monitoraggio dell'integrità e redazione dei dati personali sensibili.
Molto del lavoro è stato svolto da Keller di notte, nei ritagli di tempo dal suo lavoro, che ha lasciato dopo qualche settimana sopraffatto dalle ore passate sui file, come racconta nel pezzo di Wired.
Poi sono arrivate le altre persone, la comunità. Oltre 325 revisori volontari hanno completato più di 6.800 revisioni di documenti, con oltre 4.300 valutazioni raggiunte per consenso. Registrandosi al sito si diventa utenti in collaborazione, si possono segnalare errori, proporre correzioni, inviare nuovi documenti e partecipare al forum o al server Discord. C'è anche una sezione di reportage originale, la "newsroom" interna, con inchieste collaborative basate sui documenti indicizzati.
Nel mese di febbraio il sito ha registrato picchi di 137mila visitatori unici in un singolo giorno. Ma, dice Keller a Wired:
Anche se il traffico scendesse a dieci persone al giorno, queste dieci persone potrebbero includere una giornalista che segue una pista, una ricercatrice che scrive un saggio, o una sopravvissuta che cerca il proprio nome nei documenti. È abbastanza.
La dataviz della settimana
È il grafo creato da Keller per mappare le connessioni tra persone, luoghi e scambi di favori. La rete che ha permesso a Epstein di mantenere in piedi un sistema di abusi, traffico di esseri umani e violenze per più di 30 anni (meglio esplorarlo sul sito originale, anche con i filtri per categoria di persona - politico, accademico, ecc, e di tipo di relazione).

Lo so, tanta roba. Ma avete qualche giorno di vacanza per metabolizzare. Ci risentiamo mercoledì prossimo!